![]()
![]()
![]()
 Kampen om “det sociale internet”, altså hvor vi levende mennesker kommunikerer med hinanden, fortsætter. De to store i arenaen hedder Facebook og Google.
Kampen om “det sociale internet”, altså hvor vi levende mennesker kommunikerer med hinanden, fortsætter. De to store i arenaen hedder Facebook og Google.
Google lancerer Google Buzz, Facebook lancerer Open Graph og Social Plugins.
Nu ser det ud til, at Google har lanceret endnu en tjeneste. Det er muligt, den ikke er ny, men jeg har ikke set den før.
Det går i al sin enkelthed ud på, at der i bunden af søgeresultaterne er nogle resultater på samme søgning, men hvor der i stedet er søgt i din “social circle”, altså sociale omgangskreds på nettet.
Et eksempel er en søgning på “Further”. En ret generel søgning. Her får jeg en række resultater, blandt andet definitioner på ordet – men min sociale omgangskreds ved, hvad det er jeg søger:
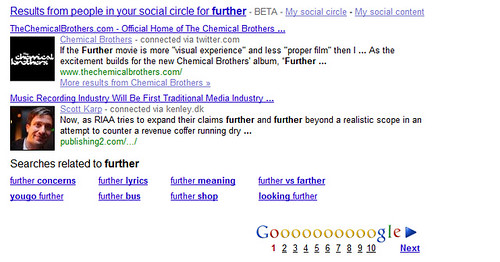
Klik på billedet for at se det i original størrelse
“Further” er nemlig også titlen på det kommende album med The Chemical Brothers. Hemmeligheden er, at Google her søger på indhold fra de mennesker, jeg er forbundet med på nettet.
Klikker jeg på “My social circle”-linket, lander jeg på denne Google-side (kræver at du er logget ind), hvor jeg kan se en alfabetisk liste over de personer, der er i min sociale omgangskreds – samt hvilke websites, den søger på indhold fra, eksempelvis Facebook, Twitter, Google Reader, Flickr etc., men også personlige websites tages med i søgningen.
Interessant 🙂
Jeg har tidligere (her og her) brokket mig over Twitter og Twitter Search angående, at de er for kronologiske og uden mulighed for at filtrere efter andet end tid.
Det lader til, at der nu er en service på vej, der kan hjælpe mig og andre med samme problem. Blogsøgemaskinen Technorati lancerer nemlig en Twitter-søgemaskine kaldet “Twittorati“, skriver TechCrunch-bloggen.
Og det lader til, at der her er noget at komme efter:
The blogs that are ranked vary by subject, with The Huffington Post taking the top spot, TechCrunch as no. 2 and Engadget in the no. 3.
Twittorati pulls Tweets into a real-time stream (though not fully real-time; like Twitter, you still need to refresh the page to get real-time results) where you can organize Tweets by Authority Ranking or by latest Tweet. (min fremhævning)
Indtil videre lader dog dog til, at man kun kan se, hvad folkene bag de blogs, der befinder sig i Technoratis top 100 skriver om på Twitter.
Læs mere hos TechCrunch:
Som jeg skrev om i indlægget “The Economist: Twitter slog CNN, men “old media” kom godt igen. Gik Twitter i selvsving?“, går Twitter hurtigt i selvsving og man drukner i mere eller mindre ligegyldige tweets.
Og det er ikke kun angående Iran, at det er et problem. I disse dage er der Reboot-konference i København, og da jeg ikke deltager, har jeg planlagt at følge med via Twitter.
For at sikre forvirring er der to Twitter-“hashtags” fra Reboot (#reboot11 og #rb11), som kan gøre det svært at følge med.
Men Twitter har også et problem. Ret ligegyldige tweets (som at folk er ved at gøre sig klar til Reboot eller er ankommet til Kedelhallen) bliver fuldstændig ligestillet med mere interessante tweets, som rent faktisk handler om de ting, der sker og bliver talt om på Reboot.
Det skyldes, at Twitter Search er baseret på her-og-nu og kun arbejder med søgeresultater ud fra et parameter: Tid.
Det fik mig til at skrive på Twitter:
Still waiting for the first valuable tweets from Reboot 11 instead of “i’m at reboot” or “heading to reboot” 🙂 #
Og en kollega giver mig ret:
@larskjensen Agree. This really is a huge problem for twitter feeds. How on earch can we cut the crap and get proper information? #
Og det skriver, tror jeg, ret godt det problem, der er med Twitter. Selvfølgelig er det smart at kunne følge med i realtime, men ikke hele tiden og ikke i alt.
Samtidig er Twitter også meget sårbar overfor “hashtag-spam”, som dette tweet, der tydeligvis blot hægter sig på nogle af de ting, der bliver talt om på Twitter:
LATENIGHT TWITS FOLLOW ME:: shaq lebron iran #iranelection lebron cavs transformers 2 What nkotb song goodnight #reboot11 #
Der mangler ganske enkelt en algoritme, som kan sortere “vigtige” og relevante tweets højere end andre. Det kunne blive baseret på følgende:
..men der er sikkert mange flere muligheder. Faktum er i hvert fald, at al information drukner i al information på Twitter i øjeblikket. Som jeg skrev i et senere tweet: Vi har brug for en Google til Twitter. Her er et bud, som dog nok skal modificeres en del 🙂
Tilbage i februar måned læste jeg hos Silicon Alley Insider om nogle mærkelige autoforslag, Google kom med, når man skrev “I am extremely”. Det første forslag var nemlig “I am extremely terrified of Chinese people”.
I dag ville jeg så tjekke, om det stadig er sådan. Og ja, det er det.

Klik for at se billedet på Flickr
Og så undrer man sig jo. For er det en joke (Google-folkene er mere eller mindre kendte for at lægge forskellige jokes og referencer ind hist og her), eller er der en fornuftig grund? Og jo, det er der.
Google autoforslag baseres på, hvad folk googler efter. Google skriver selv:
As you type, Google Suggest communicates with Google and comes back with the suggestions we show. If you’re signed in to your Google Account and have Web History enabled, suggestions are drawn from searches you’ve done, searches done by users all over the world, sites in our search index, and ads in our advertising network. If you’re not signed in to your Google Account, no history-based suggestions are displayed
Er der for eksempel lige pludselig mange, der Googler på “Hvor er Mogens Amdi?”, ja så vil den dukke op som autoforslag, når du skriver “Hvor er”. Altså må der være mange, der har googlet “I Am Extremely Terrified Of Chinese People”. Hvorfor?
Læser man i kommentarerne til indlægget på Silicon Ally Insider, falder man hurtigt over svaret; et link til denne artikel på Christwire.org, som bærer overskriften, ja rigtigt gættet, “I Am Extremely Terrified Of Chinese People”.
Så det er altså artiklen på det kristne Christwire.org, der har fået folk til at google den specifikke sætning. Det svar lå også i en af kommentarerne hos Silicon Alley insider:
To echo Bryant above, Google is displaying this suggestion because of the uproar this article http://christwire.org/2009/02/i-am-extremely-terrified-of-chinese-people/ is causing.
Blot endnu et eksempel, at vi hurtigt kan få en forklaring, hvis vi snakker sammen og bruger de muligheder, der ligger i tovejs-medierne.
På det seneste er jeg i min statistik (via MyBlogLog) begyndt at se et antal referrals (altså henvisninger) fra Microsofts Windows Live Search.
Det er der som sådan ikke noget mærkeligt i, hvis ikke det var fordi, at jeg tidligere aldrig har fået henvisninger fra Windows Live Search. Det kunne selvfølgelig skyldes, at flere er begyndt at bruge søgemaskinen. Men henvisningerne kommer fra søgninger på generiske ord som “medier”, “december”, “boersen”, “soeren”, men også “medieblogger”, som dog synes mere reel.
Det pudsige er, at jeg ud fra min statistik kan se, at henvisningerne er kommet fra den første side i søgeresultaterne. Og det giver ingen mening, for hvis du søger efter fx “december” eller “boersen” på Windows Live Search, så dukker min blog slet ikke op.
Der fik mig til at skrive et tweet:
All of a sudden I’m getting a pretty amount of referrals from Microsoft’s Live Search. What’s up with that?
Inden længe var der svar fra Frank H Madsen:
@larskjensen Meget mærkeligt. Er det mon Live, der referal-spammer igen?
Frank gav mig også et link til denne Google-søgning, og på den første side, som søgningen returnerede, læser jeg noget, som jeg kan genkende:
I have been seeing referrers from search.live.com for some strange and very generic keywords, things like “article”, “design”, and “sites”. Visiting the referring URL returned no link back to any of my sites.
Altså præcis det samme som jeg har oplevet. Dengang i juli var det MSN Search, det drejede sig om. Den, som i dag hedder Windows Live Search.
Et andet sted står under overskriften “Yell if Microsoft’s Live.com Spammed You Too“:
These referer headers are spoofed as the keywords from these supposed searches are sometimes in no way related to the requested page. Additionally, for most of the other supposed searches, the requested pages do not rank in the top 10 (first page of results) in a way to send this traffic.
Et tredje sted står at læse, at der er tale om “officielle test” fra Microsofts side:
First, we appreciate the concerns and issues that have been raised and apologize for any inconvenience this might have caused.
Second, we want to explain what this is all about. The traffic you are seeing is part of a quality check we run on selected pages. While we work on addressing your concerns, we would request that you do not actively block the IP addresses used by this quality check; blocking these IP addresses could prevent your site from being included in the Live Search index.
Please keep the feedback and thoughts coming as we will use this to help improve this process and make sure that it impacts your sites as little as possible.
thanks
– msndude (msd)
Så er spørgsmålet så, om Microsoft kører disse test igen. Noget kan tyde på det. Men hvad er så meningen med disse “quality checks”? Hvordan kan man teste sine systemer ved at forfalske en henvisning fra side x til side y, skønt der ikke optræder et link til side y på side x? Det giver ingen mening for mig.
Irriterende er det i hvert fald, da det giver støj i min statistik — lige præcis den statistik, jeg bruger mest: Den hvor jeg kan se, hvordan folk lander her på denne blog.
| Tidspunkt | Søgestreng |
| 00:39 | pressemeddelelser |
| 02:46 | youtube |
| 04:02 | economist |
| 04:19 | blogs |
| 07:02 | medieblogger |
| 07:17 | medier |
| 09:42 | forside |
En ting, som en del Google-konkurrenter har spillet på er muligheden for at relaterer søgninger til hinanden. Altså “du har søgt på X – måske du også bør søge på Y”.
Nu har Google imidlertid lanceret sin egen feature med relatered søgninger, skriver australske The Age:
Google’s new search feature purports to “better understand associations and concepts related to your search”, and therefore to deliver a more meaningful search experience.
This is achieved by integrating a new technology into the Google search infrastructure that enables a better understanding of concepts and associations related to the search query.
All of it pocessed in real time and in any one of 37 different languages.
Blandt de 37 sprog finder vi dansk, en søgning på “ekstra bladet” giver for eksempel følgende:
I dag fik jeg mail fra holdet bag den svenske blogsøgemaskine Twingly om, at de har lanceret en mikroblogsøgning.
Søgetjenesten indekserer blandt andet Twitter (hvor man i forvejen kan søge via Twitter Search, tidligere Summize), Jaiku (som har manglet en feature som denne), identi.ca.
Da jeg den 18. januar skrev om Jaikus tabte potentiale, efterlyste jeg blandt andet en søgemaskine til Jaiku, og den har vi altså fået nu. Desværre for sent.
Hvis Googles plan er, at Jaiku bliver en service, man skal kunne bruge i sin organisation/virksomhed, så bliver det interessant at se, hvordan Twingly mikroblogsøgemaskinen vil håndtere det?
I dag da jeg Google “IT Factory” opdagede jeg, at man stadig kan se, de sider fra deres hjemmeside, som Google har cachet (altså gemt), inden IT Factory lukkede hjemmesiden.
Der er blandt andet denne side, der indeholder nyheder om IT Factory fra 11. november 2008, blandt andet:
IT Factory udleverer fremover kun økonomiske- og regnskabsoplysninger såfremt disse er revideret af selskabets revisor.
Det kan man måske egentlig godt forstå.
Wayback Machine har gemte sider fra itfactory.com fra 6. december 1998 til 4. februar 2008.
Mens de formentlig bliver liggende, så rydder Google løbende op i cachen, så det skal være nu, inden det er for sent, hvis der skal findes noget der.
Da jeg for et stykke tid siden var på besøg på Journalisthøjskolen for at tale om nye medier, skulle jeg vise et kort, som Politiken havde lavet.
Jeg kunne ikke finde kortet ved at søge på politiken.dk, og i stedet fandt jeg det ved at søge via Google.
Nu ville jeg lige teste, om søgefunktionen på Politikens netavis egentlig gør det, den skal. Prøv en søgning på “skyderier københavn” på politiken.dk:
Søgningen gav ingen resultater
Så prøver vi samme søgning på Google, denne gang med “site:politiken.dk” inkluderet for at indikere, at vi kun vil søge på politiken.dk:
Resultaterne 1 – 10 ud af ca. 1.230 fra politiken.dk for skyderier københavn.
Google er med andre ord langt bedre til at finde indhold på politiken.dk end Politikens egen søgemaskine. Det ville jeg måske lige notere mig, hvis jeg arbejdede med teknikken på politiken.dk.
